
이번 글은 아래의 글을 공부하면서 나름의 번역본을 정리한 것임을 밝힌다. (⚠️내맘대로 의역 심함 주의)
Why Python is Slow: Looking Under the Hood | Pythonic Perambulations
So Why Use Python?¶ Given this inherent inefficiency, why would we even think about using Python? Well, it comes down to this: Dynamic typing makes Python easier to use than C. It's extremely flexible and forgiving, this flexibility leads to efficient use
jakevdp.github.io
우리는 모두 '파이썬은 느리다'라는 말을 들어본 적이 있다.
나는 컴퓨터공학에서 파이썬을 강의할 때, 강의 초반에 항상 이 점을 언급하며, 그 이유를 설명한다.
파이썬은 값이 연속된 버퍼가 아닌, 흩어진 객체에 저장되는 동적 타입의 인터프리터 언어라는 것이 핵심이다.
그 다음 연산의 벡터화를 도와주는 Numpy, Scipy 같은 툴과, 컴파일된 코드의 확인을 통해서 이를 확인해본다.
하지만, 나는 최근에 파이썬 입문자들에게는 "동적 타입의, 인터프리터 언어, 버퍼, 벡터화, 컴파일된" 등의 단어가 이해하기 힘들다는 사실을 알게되었다. 입문자들은 위 용어들이 정확하게 어떤 방식으로 작동하는지를 이해하기 어려울 것이다.
그래서 나는 이 포스트를 쓰기로 결심했고, 이번 포스트에서 그 동안 내가 얼버무렸던 디테일을 제대로 짚어보려 한다.
이 과정에서 우리는 CPython 자체의 진행 상황을 살펴보기 위해 파이썬의 표준 라이브러리를 사용할 것이다.
나는 당신이 초보자이든, 전문가이든 앞으로의 탐구에서 무언가를 배울 수 있기를 바란다.
왜 파이썬은 느린가
파이썬은 다양한 이유로, Fortran과 C보다 느리다.
1. 파이썬은 동적 타입 언어이다.(↔️ 정적 타입 언어)
이는 프로그램이 실행될 때, 인터프리터는 정의된 변수의 타입을 모른다는 의미이다. C언어에서의 변수와 파이썬에서의 변수 차이는 아래의 그림으로 요약할 수 있다.
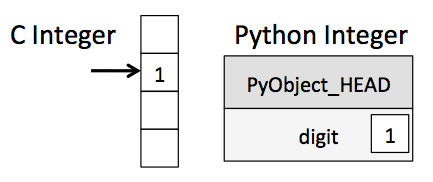
C에서 컴파일러는 변수의 정의에 의해 변수의 타입을 알고 있다. 반면 파이썬에서 프로그램이 실행될 때 인터프리터가 아는 것은, 변수가 일종의 파이썬의 객체라는 사실 뿐이다.
*️⃣ [참고] 변수의 선언(declaration)과 정의(definition)의 차이?
선언과 정의의 가장 큰 차이는 "메모리를 할당하는가"이다.
선언: 변수에 메모리를 할당하지 않고, 이름만 지정함
정의: 변수에 메모리를 할당함
C에서 아래의 코드를 작성했다고 하자.
/* C code */
int a = 1;
int b = 2;
int c = a + b;C 컴파일러는 처음부터 변수 a와 b가 int라는 것을 알고 있다. a와 b는 int외에 다른 값을 가질 수 없다!
이를 통해, 컴파일러는 두 개의 int를 더하는 함수를 호출하고, 이는 또 다른 int를 반환한다.
이 과정을 정리하면 아래와 같다.
C 덧셈
- <int> 1 을 변수 a에 할당
- <int> 2 를 변수 b에 할당
- binary_add<int, int>(a, b)를 호출
- 결과를 변수 c에 할당
동일한 코드를 파이썬으로 작성해보자.
# python code
a = 1
b = 2
c = a + b여기서 인터프리터는 1과 2가 객체라는 것만 알고 있고, 그 객체가 어떤 타입인지는 알지 못한다.
따라서 인터프리터는 각 변수의 타입에 대한 정보를 얻기 위해 먼저 PyObject_HEAD 를 확인해야 한다. 그리고나서 두 타입에 적절한 덧셈 함수를 호출한다. 마지막으로 인터프리터는 덧셈의 결과를 저장하기 위해 새로운 객체를 생성하고 초기화 해야 한다. 이 과정을 대략적으로 정리하면 아래와 같다.
Python 덧셈
- 변수 a에 1 할당
- a -> PyObject_HEAD -> typecode 를 int로 설정
- a -> val 을 1 로 설정
- 변수 b에 2 할당
- b -> PyObject_HEAD -> typecode 를 int로 설정
- b -> val 을 2 로 설정
- binary_add(a, b) 호출
- a -> PyObject_HEAD -> typecode 확인
- a 가 int임을 확인
- b -> PyObject_HEAD -> typecode 확인
- b 가 int임을 확인
- binary_add<int, int>(a -> val, b -> val) 호출
- 위 함수의 result 반환받음
- 파이썬 객체인 c를 생성
- c -> PyObject_HEAD -> typecode 를 int로 설정
- c -> val 을 result 로 설정
동적 타입핑이라는 것은 모든 작업의 단계가 훨씬 많아진다는 것을 의미하며, 이 것이 바로 파이썬이 C에 비해 숫자 데이터에 대한 작업에서 느린 이유이다.
2. 파이썬은 인터프리터 언어이다.(↔️ 컴파일 언어)
우리는 위에서 인터프리터 코드와 컴파일 코드의 차이점을 한 가지 확인했다. 스마트 컴파일러는 반복적이거나 불필요한 연산을 미리 확인하고 최적화할 수 있고, 그에 따라 속도를 높일 수 있다. 컴파일러 최적화는 그 자체로 할 이야기가 많고, 나는 그 분야에 대한 전문가가 아니기 때문에 여기까지만 말하도록 하겠다. 더 자세한 예시가 궁금하다면 나의 이전 포스트를 확인해보길 바란다. Numba vs. Cython: Take2
3. 파이썬의 객체 모델은 비효율적인 메모리 액세스를 초래한다.
우리는 위에서 C 정수에서 파이썬 정수로 넘어갈 때 타입 정보에 관한 추가 레이어를 거친다는 사실을 확인했다.
이런 정수를 여러 개 가지고 있고, 이를 한번에 모아서 연산하고 싶은 경우를 생각해보자.
이 때 파이썬에서는 표준 List 객체를 사용할 수 있고, C에서는 버퍼 기반 배열을 사용할 수 있다.
가장 간단한 형태의 Numpy 배열은 C 배열을 기반으로 구축된 파이썬 객체이다. 즉, 값이 연속적인 메모리(버퍼)에 저장되어 있고, 이 버퍼를 가리키는 포인터를 가지고 있다는 의미이다. 반면 파이썬에서의 List는 포인터들이 연속적인 메모리(버퍼)에 저장되어 있고, 이 버퍼를 가리키는 또 다른 포인터를 가진다. 버퍼에 저장된 포인터들은 각각 실제 값(데이터)에 대한 참조가 있는 파이썬 객체를 가리킨다. 이 내용을 그림으로 그리면 아래와 같다.
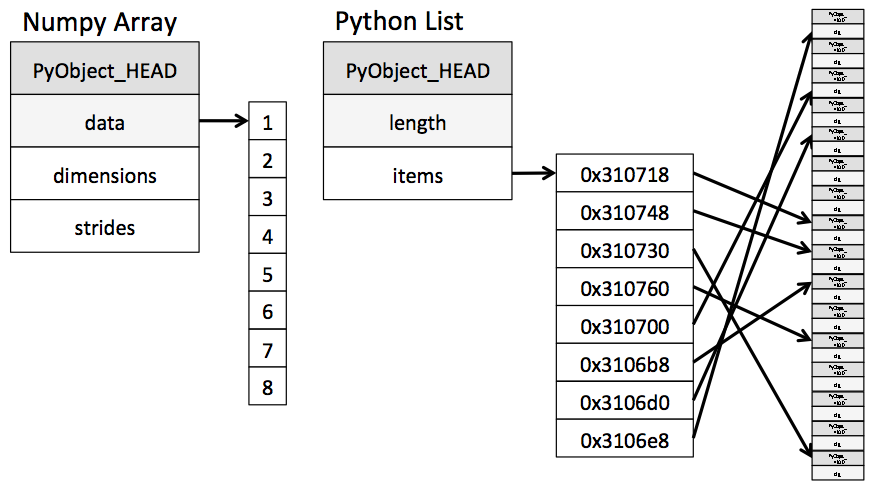
데이터를 순차적으로 처리하는 연산을 수행하는 경우, 스토리지 비용과 액세스 비용 모두에서 Numpy를 사용하는 것이 파이썬 List를 사용하는 것보다 훨씬 효율적인 것을 확인할 수 있다.
그럼 파이썬을 왜 사용하는걸까?
이렇듯 파이썬이 본질적으로 비효율적임에도 불구하고, 우리가 파이썬 사용을 고려하는 이유는 무엇일까?
그 이유는 동적 타입핑이 C보다 파이썬을 사용하기 쉽게 만들어 주기 때문이다. 파이썬의 매우 유연하고 관대한 특성 덕에 개발 시간을 효율적으로 사용할 수 있고, C나 Fortran을 사용한 최적화된 코드가 필요한 경우에는, 컴파일 라이브러리를 통해 쉽게 코드를 연결할 수도 있다. 이것이 많은 공학 커뮤니티에서 파이썬 사용이 지속적으로 증가하고 있는 이유이다. 정리하면, 파이썬은 전반적인 공학 프로그래밍에 효율적인 언어라는 것이다.
파이썬 해킹하기(아닐수도?)
위에서 파이썬이 실행되는 내부 구조에 대해 이야기했다. 하지만 여기서 끝내기는 아쉬운 감이 있다. 위의 내용을 정리하면서 나는 파이썬 언어의 내부를 해킹하기 시작했고, 그 과정 자체에서 배울 점이 많다는 것을 알게 되었다.
지금부터는 파이썬 자체를 사용해서 파이썬 객체를 보여주는 해킹을 함으로써 위에서 설명한 내용이 정확하다는 것을 증명할 것이다. 아래의 코드는 모두 Python3.4를 사용하여 작성되었으며, 버전에 따라 객체의 내부 구조가 조금씩 다를 수 있다. 또한 앞으로 나오는 코드들은 64비트 CPU를 가정한다. 만약 32비트 CPU를 사용한다면, C 타입 중 일부를 수정해야 할 것이다.
파이썬 Integer 톺아보기
파이썬에서 integer는 사용하기 매우 쉽다.
x = 42
print(x)
# output
42그러나, 이렇게 인터페이스가 단순할수록 그 밑에서 벌어지는 일들이 복잡함을 예상할 수 있다. 위에서 우리는 파이썬 integer의 메모리 레이아웃에 대해 간략하게 살펴봤다. 여기서는 파이썬의 내장 모듈인 ctypes를 사용해서 파이썬 인터프리터 자체에서의 파이썬 integer 타입을 확인할 것이다. 그러나 먼저 C API 수준에서 파이썬 integer가 어떻게 보이는지를 정확하게 알아야 한다.
CPython에서 변수 x는 실제로 CPython의 Include/longintrepr.h 소스코드에 정의된 structure(구조체) 안에 저장된다.
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};PyObject_VAR_HEAD 는 아래의 struct로 객체를 생성하기 시작하는 매크로이다. 아래의 struct는 Include/object.h 에 정의되어 있다.
*️⃣ [참고] C에서 macro(매크로)란?
C에서 #define로 정의되며, 프로그램 내에서 컴파일러가 특정 키워드를 만났을 때, 대체할 값을 정의하는 것을 말한다.
#define N 100
int a[N];
위 코드처럼 사용할 수 있다.
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;위 struct에 포함되어 있는 PyObject는 아래와 같다. 이 역시 Include/object.h 에 정의되어 있다.
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;_PyObject_HEAD_EXTRA 는 파이썬 빌드에서 일반적으로 사용되지 않는 매크로이다.
typedefs와 매크로들이 난독화되지 않은 상태일 때, 위에서 본 모든 struct를 합쳐서 표현하면 아래와 같이 나타낼 수 있다.
struct _longobject {
long ob_refcnt; /* 객체에 대한 참조 카운트 */
PyTypeObject *ob_type; /* 객체에 대한 모든 타입 정보와 메서드 정의를 포함하는 구조체를 가리키는 포인터 */
size_t ob_size;
long ob_digit[1]; /* 실제 integer 값 */
};이제 C API 수준에서 파이썬 integer의 구조를 확인했으니, ctypes 모듈을 사용해서 실제 객체 구조를 확인해보자.
먼저 C structure의 파이썬 표현을 정의하는 것부터 시작하자.
import ctypes
class IntStruct(ctypes.Structure):
_fields_ = [("ob_refcnt", ctypes.c_long),
("ob_type", ctypes.c_void_p),
("ob_size", ctypes.c_ulong),
("ob_digit", ctypes.c_long)]
def __repr__(self):
return ("IntStruct(ob_digit={self.ob_digit}, "
"refcount={self.ob_refcnt})").format(self=self)이제 특정 숫자 42을 나타내는 내부 구조를 확인해보자. 우리는 CPython에서 객체의 메모리 주소를 반환하는 id() 함수를 사용할 것이다.
num = 42
IntStruct.from_address(id(42))
# output
IntStruct(ob_digit=42, refcount=35)ob_digit은 제대로 42를 나타내고 있음을 확인할 수 있다.
그런데 refcount는 왜 저럴까? 우리는 변수를 1개밖에 생성하지 않았다. 왜 참조 카운트가 1보다 클까?
파이썬은 작은 integer를 많이 사용한다. 이 integer 각각에 대해서 매번 새로운 PyObject가 생성된다면, 많은 메모리가 필요할 것이다. 이 때문에 파이썬은 싱글톤으로 일반적인 정수값을 구현한다.즉, 해당 숫자가 메모리에 딱 1개만 존재한다는 말이다. 0~255 범위에 속한 integer를 생성할 때마다 해당 값을 가진 싱글톤에 대한 참조를 생성하게 된다.
x = 42
y = 42
id(x) == id(y)
# output
True두 변수 x, y 모두 같은 메모리 주소를 가리키는 포인터이다. 더 큰 integer(Python3.4 기준 255보다 큰 정수)를 생성하면 어떻게 될까?
x = 1234
y = 1234
id(x) == id(y)
# output
False 더 이상 두 포인터는 같은 메모리를 가리키지 않는다.
파이썬 인터프리터를 시작하는 것만으로도 많은 integer 객체가 생성된다. 각 객체에 대한 참조 카운트를 확인해보는 것도 재미있을 것이다.
%matplotlib inline
import matplotlib.pyplot as plt
import sys
plt.loglog(range(1000), [sys.getrefcount(i) for i in range(1000)])
plt.xlabel('integer value')
plt.ylabel('reference count')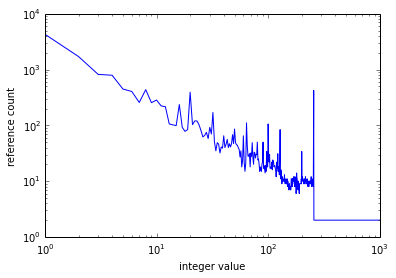
위 그래프를 보면, 0이 수천 번 참조되고, 일반적으로 integer의 크기가 증가함에 따라 참조 카운트가 감소하는 것을 확인할 수 있다.
0~255까지의 integer의 경우, ob_digit의 값과 실제 integer값이 동일함을 아래 코드로 확인할 수 있다.
all(i == IntStruct.from_address(id(i)).ob_digit for i in range(256))
# output
True여기서 조금 더 깊이 가보면, 256 이상의 integer는 ob_digit 값과 실제 integer의 값이 동일하지 않은 것을 확인할 수 있다. 이는 일부 bit-shift 연산이 Objects/longobject.c 에서 실행되고, 이로 인해, 큰 integer의 메모리에서의 표현 방식이 바뀐다.
나는 왜 이런 현상이 일어나는지 정확하게 이해하지는 못했지만, 아래의 경우처럼, long 범위를 초과하는 정수를 문제없이 처리하는 파이썬의 기능과 관련이 있을 것 같다고 생각한다.
2 ** 100
# output
1267650600228229401496703205376위 숫자는 long 타입의 범위인 2^64를 초과했는데도, 문제없이 처리된다.
파이썬 List 톺아보기
위에서 사용한 방법을 파이썬 list에도 적용해보자. Include/listobject.h 에서 list의 구조체를 찾아보자.
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;역시, typedefs와 매크로들이 난독화되지 않은 상태일 때, 위에서 struct를 하나로 합쳐서 표현하면 아래와 같다.
typedef struct {
long ob_refcnt; /* 객체에 대한 참조 카운트 */
PyTypeObject *ob_type; /* 객체에 대한 모든 타입 정보와 메서드 정의를 포함하는 구조체를 가리키는 포인터 */
Py_ssize_t ob_size; /* list가 가지고 있는 아이템의 수 */
PyObject **ob_item; /* list 각각의 아이템을 가리키는 포인터 */
long allocated;
} PyListObject;이를 파이썬으로 표현해보자.
class ListStruct(ctypes.Structure):
_fields_ = [("ob_refcnt", ctypes.c_long),
("ob_type", ctypes.c_void_p),
("ob_size", ctypes.c_ulong),
("ob_item", ctypes.c_long), # PyObject** pointer cast to long
("allocated", ctypes.c_ulong)]
def __repr__(self):
return ("ListStruct(len={self.ob_size}, "
"refcount={self.ob_refcnt})").format(self=self)이제 아래의 코드를 실행해보자.
L = [1,2,3,4,5]
ListStruct.from_address(id(L))
# output
ListStruct(len=5, refcount=1)L에 대한 참조를 추가하고 참조 수를 다시 확인해보자.
tup = [L, L] # two more references to L
ListStruct.from_address(id(L))
# output
ListStruct(len=5, refcount=3)이제 list에 담긴 아이템의 실제 값을 찾아보자.
위에서 보았다시피, list에서 요소들은 PyObject를 가리키는 포인터들의 연속적인 배열을 통해서 저장된다. ctypes 모듈을 사용해서 IntStruct 객체로 구성된 복합 구조를 만들어보자.
# 리스트의 새로운 포인터 얻기
Lstruct = ListStruct.from_address(id(L))
# L의 길이와 같은 크기의 integer pointer 배열 타입을 생성
PtrArray = Lstruct.ob_size * ctypes.POINTER(IntStruct)
# 위에서 생성한 타입의 객체 생성
L_values = PtrArray.from_address(Lstruct.ob_item)이제 각 아이템의 값을 확인해보자.
[ptr[0] for ptr in L_values] # ptr[0] dereferences the pointer
# output
[IntStruct(ob_digit=1, refcount=5296),
IntStruct(ob_digit=2, refcount=2887),
IntStruct(ob_digit=3, refcount=932),
IntStruct(ob_digit=4, refcount=1049),
IntStruct(ob_digit=5, refcount=808)]list에서 PyObject의 integer값을 복구해냈다! 이제 잠시 시간을 내서 이해하는 시간을 가지길 바란다.
파이썬 Numpy array 톺아보기
이제 동일한 과정을 Numpy array에 적용해보자. Numpy array의 C API 수준 표현은 건너뛰도록 하겠다. 궁금하다면 numpy/core/include/numpy/ndarraytypes.h 를 확인해보자.
여기서는 Numpy 버전 1.8을 사용하고 있다. 버전에 따라 내부 구조가 변경되었을 수 있다.
먼저 Numpy array를 파이썬에서 structure로 표현하는 것부터 시작하자. shape과 strides를 지원하는 파이썬 버전에 접근하기 위해 커스텀 프로퍼티를 추가할 것이다.
class NumpyStruct(ctypes.Structure):
_fields_ = [("ob_refcnt", ctypes.c_long),
("ob_type", ctypes.c_void_p),
("ob_data", ctypes.c_long), # char* pointer cast to long
("ob_ndim", ctypes.c_int),
("ob_shape", ctypes.c_voidp),
("ob_strides", ctypes.c_voidp)]
@property
def shape(self):
return tuple((self.ob_ndim * ctypes.c_int64).from_address(self.ob_shape))
@property
def strides(self):
return tuple((self.ob_ndim * ctypes.c_int64).from_address(self.ob_strides))
def __repr__(self):
return ("NumpyStruct(shape={self.shape}, "
"refcount={self.ob_refcnt})").format(self=self)이제 아래 코드를 실행해보자.
x = np.random.random((10, 20))
xstruct = NumpyStruct.from_address(id(x))
xstruct
# output
NumpyStruct(shape=(10, 20), refcount=1)아래 코드를 통해 데이터의 shape과 참조 카운트가 제대로 작동함을 확인할 수 있다.
L = [x,x,x] # add three more references to x
xstruct
# output
NumpyStruct(shape=(10, 20), refcount=4)이제 데이터 버퍼를 꺼내는 작업을 해보자! 단순하게 만들기 위해 우리는 strides를 무시하고 C-연속 배열이라고 가정하자. 이는 약간의 작업으로 일반화할 수 있다.
x = np.arange(10)
xstruct = NumpyStruct.from_address(id(x))
size = np.prod(xstruct.shape)
# assume an array of integers
arraytype = size * ctypes.c_long
data = arraytype.from_address(xstruct.ob_data)
[d for d in data]
# output
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]변수 data가 Numpy array에서 정의된 연속된 메모리 블록을 나타냄을 알 수 있다. x 배열의 값을 바꾸고 data 에도 적용이 되는지 확인해보자.
x[4] = 555
[d for d in data]
# output
[0, 1, 2, 3, 555, 5, 6, 7, 8, 9]x의 요소를 수정했을 때, 이 값이 data에도 적용됨을 확인할 수 있다. 변수 x와 data 모두 같은 연속된 메모리 블록를 가리키고 있기 때문이다.
파이썬 List와 Numpy array를 내부를 비교해보면, Numpy array가 동일한 타입의 데이터들을 표현하는데 훨씬 간단하다는 것을 분명하게 알 수 있다. 이 때문에 컴파일러는 파이썬 List보다 Numpy array를 훨씬 효율적으로 처리할 수 있다.
그냥 재미로: "절대 사용하면 안되는" 몇가지 해킹 방법
➡️ 원문을 보는 것을 추천한다. 꽤 재미있음😁 (시간이 오래걸려서 이 부분은 넘겨야겠다.)
결론
파이썬은 느리다. 이는 개발자가 빠르고 쉽고 재미있게 프로그래밍할 수 있도록 도와주는 동적 타입을 사용하기 때문이다. 그리고 우리가 앞서 본 것처럼, 파이썬은 파이썬 객체 내부 구조를 살펴볼 수 있는 자체 툴을 제공한다.
이 포스트를 통해 다양한 객체들 간의 차이점과 CPython의 내부 작동 원리가 명확해지길 바란다. 이번 탐구는 나에게도 매우 유익한 시간이었고, 당신에게도 그랬기를 바란다!
'Python' 카테고리의 다른 글
| [Python] GIL(Global Interpreter Lock)이란? (1) | 2022.11.21 |
|---|---|
| [Python] 파이썬에서의 비동기 이해하기 (feat. asyncio) (2) | 2022.11.16 |