
이번 글에서는 솔라나의 창립자인 아나톨리 야코벤코의 Medium 블로그 포스팅 중 하나인 Cloudbreak에 관한 내용을 공부하며 의역한 내용을 정리해 보려고 한다. 원본 글을 먼저 읽어보는 것이 좋다!
Cloudbreak — Solana’s Horizontally Scaled State Architecture
Understand 1 of 8 key technologies that make Solana the most performant blockchain in the world
medium.com
솔라나가 전세계에서 가장 성능이 좋은 블록체인이 되는 것을 가능하게 한 8가지 핵심 기술 중 1개를 이해해보자.
솔라나는 세계에서 가장 성능이 좋은 무허가형 블록체인이다. 현재 솔라나 테스트넷은, 물리적으로 구분된 200개의 노드가 GPU를 이용할 때 초당 50,000개 이상의 트랜잭션 처리량을 유지하고 있다. 이를 달성하기 위해서는 여러 최적화와 새로운 기술이 필요하며, 그 결과는 블록체인 개발에 있어 새로운 시대를 알리는 네트워크 용량의 돌파구가 된다.
솔라나 네트워크를 가능하게 하는 8가지 주요 혁신
- Proof of History (POH) - 합의 전 사용되는 clock 역할
- Tower BFT - PBFT의 PoH 최적화된 버전
- Turbine - 블록 전파 프로토콜
- Gulf Stream - Mempool-less 트랜잭션 포워딩 프로토콜
- Sealevel - 병렬로 실행되는 스마트 컨트랙트 런타임
- Pipelining - 검증 최적화를 위한 트랜잭션 처리 단위
- Cloudbreak - 수평적으로 확장된 Account 데이터베이스
- Archivers - 분산된 원장 저장소
이번 블로그 포스트에서 우리는 솔라나의 수평으로 확장된 상태(state) 아키텍처인 Cloudbreak에 대해 살펴볼 것이다.
Overview: RAM, SSDs, and Threads
샤딩없이 블록체인을 확장할 때, 연산 능력만 확장하는 것은 충분하지 않다. accounts를 계속 추적하기 위해 필요한 메모리가, 사이즈와 접근 속도 모두에 병목이 되기 때문이다. 예를 들면, 현대의 많은 블록체인에서 사용되는 로컬 DB 엔진인 LevelDB는 일반적으로 하나의 머신에서 대략 5,000 TPS 이상의 아웃풋을 지원하지 못한다고 알려져 있다. 이는 가상머신이 DB 추상화를 통한 account 상태에 대한 동시 read와 write 접근이 불가능하기 때문이다.
이에 대한 naive한 해결책은 global state를 RAM에 유지하는 것이다. 그러나, 소비자용 컴퓨터에 global state를 저장하기에 충분한 RAM이 있을 것이라고 기대하는 것은 합리적이지 않다. 그렇다면 다음 선택지는 SSDs를 이용하는 것이다. SSDs는 바이트당 접근 비용을 대략 30배 정도 줄여주지만, RAM보다는 1000배 정도 느리다. 아래는 시장에서 제일 빠른 SSD인 Samsung SSD의 최근 데이터시트이다.

단일 지출 트랜잭션은 2개의 accounts를 읽고, 1개의 account에 써야 한다. Account의 키는 암호화 Public key이며, 완전히 랜덤적이고, 실제 데이터 지역성이 없다. 사용자의 지갑에는 많은 account 주소가 있을 것이고, 각 주소의 bits는 다른 주소와 전혀 관련이 없다. account간 지역성이 없기 때문에 서로 가까이 있을수록 메모리에 배치하는 것은 불가능하다.
단일 SSD를 사용하는 accounts DB의 단순한 싱글 스레드 구현은, 초당 최대 15,000개의 고유한 읽기를 통해, 초당 최대 7,500개의 트랜잭션을 지원한다. 최신 SSD는 32개의 동시 스레드를 지원하므로, 초당 370,000개의 읽기 또는 초당 185,000개의 트랜잭션을 지원할 수 있다.
Cloudbreak
솔라나의 기본 디자인 원칙은 하드웨어를 100% 활용하는 것을 방해하지 않도록 소프트웨어를 설계하는 것이다.
32개의 스레드 간에 동시 읽기 및 쓰기가 가능하도록 account DB를 구성하는 것은 어려운 일이다. LevelDB와 같은 Vanilla 오픈 소스 DB는 블록체인 설정에서 이 특정 문제에 대해 최적화하지 않기 때문에 병목 현상을 일으킨다. 솔라나는 이러한 문제를 해결하기 위해 전통적인 DB를 사용하지 않는다. 대신, 솔라나는 OS에서 사용하는 여러가지 메커니즘을 사용한다.
먼저, 메모리에 매핑된 파일을 활용한다. 메모리 매핑 파일은 바이트가 프로세스의 가상 주소 공간에 매핑된 파일이다. 파일이 매핑되면 다른 메모리처럼 작동한다. 커널은 RAM에 캐시 메모리의 일부를 유지하거나, 전혀 유지하지 않을 수 있지만 물리적 메모리의 양은 RAM이 아닌 디스크 크기에 의해 제한된다. 읽기 및 쓰기는 여전히 디스크의 성능에 따라 결정된다.
❓ Address space(주소 공간)와 Memory의 관계
주소 공간은 프로그램이나 프로세스에서 사용할 수 있는 메모리의 유효한 주소 범위이다. 즉, 프로그램이나 프로세스가 액세스할 수 있는 메모리를 나타낸다. 메모리는 물리적 또는 가상일 수 있으며 명령을 실행하고 데이터를 저장하는 데 사용된다.
❓Virtual address space와 Virtual memory란
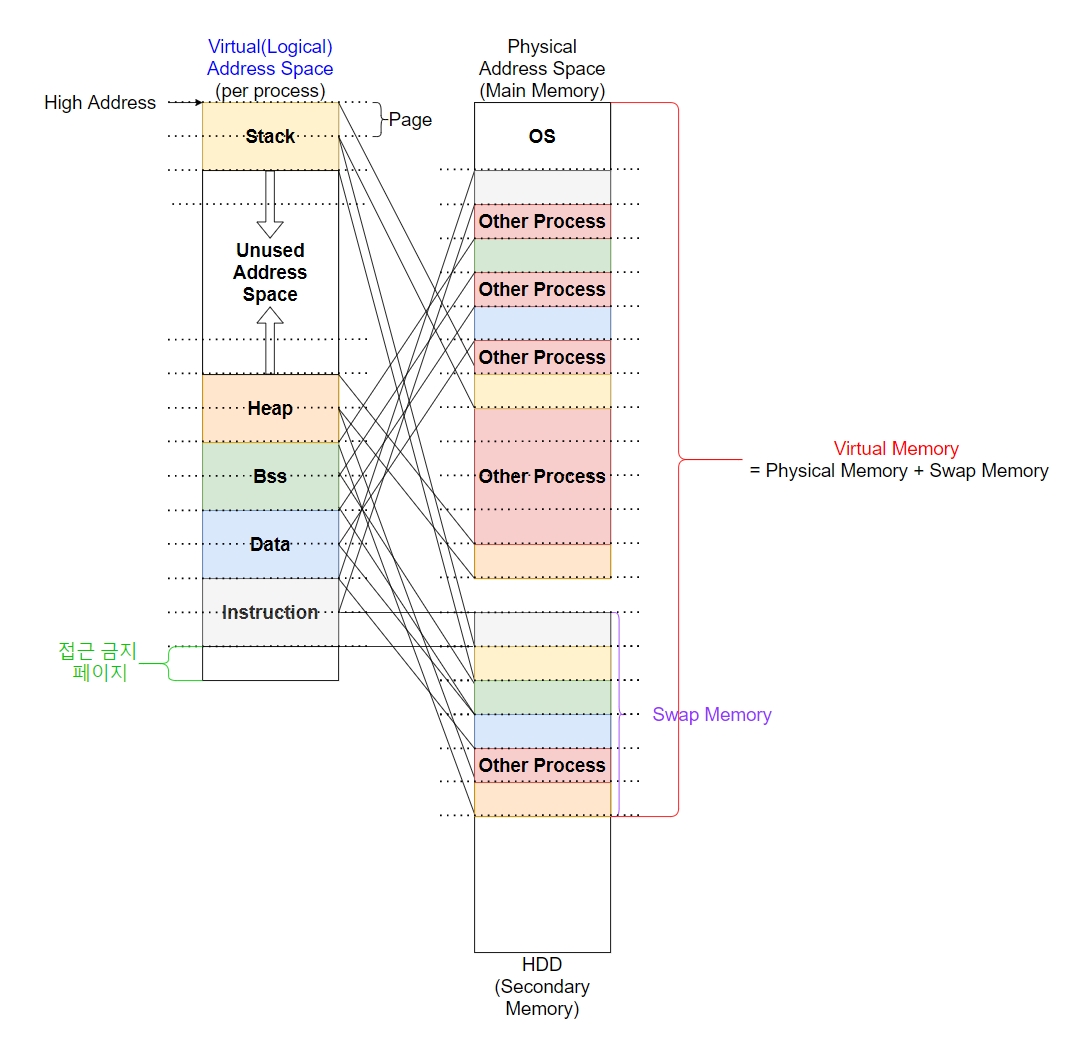
우리가 흔히 알고 있는 heap이 아래에서 올라오고 stack이 위에서 내려오는 구조의 그림이 바로 프로세스의 가상화된 주소 공간을 나타낸 것이다.
가상 메모리는 메모리 관리 기법의 하나로, 실제로 사용 가능한 기억 장치(RAM, HDD, SSD 등)를 추상화하여 프로세스 입장에서 매우 큰 RAM처럼 보이도록 만드는 것을 말한다.
❓Memory-Mapped File(MMF)이란
Memory Mapped File은 가상 메모리처럼 프로세스 주소 공간을 예약하고, 예약한 영역에 물리 저장소를 커밋하는 기능을 제공한다. 가상 메모리와 유일한 차이점이라면, 시스템의 페이징 파일을 사용하는 대신, 디스크 상에 존재하는 어떤 파일이라도 물리 저장소로 사용 가능하다는 점이다.
open(), read(), write() 시스템 호출을 사용하여 디스크에 있는 파일을 사용하면 파일이 매번 접근될 때마다 시스템 호출을 해야 하고 디스크에 접근해야 한다. 이와같은 방법 대신 IO를 메모리 참조 방식으로 대신할 수도 있다.
메모리 매핑(memory mapping)이라고 불리는 접근 방식은 프로세스의 가상 주소 공간 중 일부를 관련된 파일에 할애하는 것을 말한다.
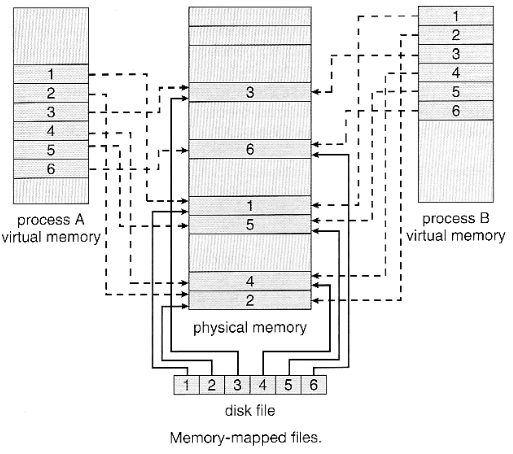
파일의 메모리 매핑은 프로세스의 페이지 중 일부를 디스크에 있는 파일의 블록에 매핑함으로써 이루어진다. 첫번째 접근은 일반적인 페이징 과정에 따라 페이지 부재를 발생시킨다. 그 때 그 파일 내용 중 페이지 크기만큼의 해당 부분이 파일 시스템으로부터 메모리 페이지로 읽혀 들어오게 된다. 그 이후 파일의 R/W는 다른 메모리 액세스와 마찬가지로 취급되어, 파일 접근과 사용을 단순하게 만들어준다. 또한 read(), write()을 호출할 때마다 소요되었던 오버헤드를 줄일 수 있다.
메모리 매핑은 여러 프로세스들이 자료 공유를 위해 사용할 수도 있다. 한 프로세스가 공유 중인 메모리 매핑에 쓰기를 하면 그 쓰기는 즉시 다른 모든 프로세스들도 볼 수 있게 된다. 그 파일을 공유하는 프로세스들의 페이지 매핑 테이블은 모두 그 파일에 대응하는 물리 메모리 상의 페이지를 가리킨다. 이 페이지에는 디스크 파일의 내용이 올라와 있다.
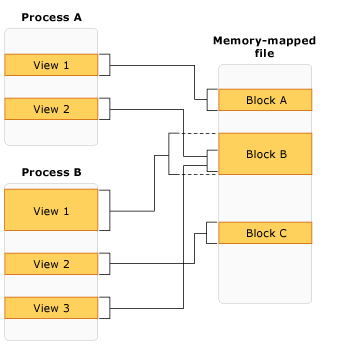
두번째 중요한 설계 고려 사항은 순차적인 작업이 랜덤적인 작업보다 훨씬 빠르다는 것이다. 이는 SSD 뿐만 아니라 전체 가상 메모리 스택에도 해당된다. CPU는 순차적으로 접근되는 메모리를 미리 가져오는 것을 잘하고, OS는 순차적 페이지 오류를 처리하는 것을 잘한다. 이러한 특징을 활용하기 위해 account 데이터 구조를 대략 아래와 같이 나눴다.
- accounts 및 forks의 인덱스는 RAM에 저장된다.
- accounts는 최대 4MB 크기의 메모리 매핑 파일에 저장된다.
- 각 메모리 맵은 하나의 fork에서 제안된 account만 저장한다.
- 맵은 가능한 많은 SSD에 무작위로 배포된다.
- Copy-on-write 의미 체계가 사용된다.
- 동일한 fork에 대한 랜덤 메모리 맵에 쓰기가 추가된다.
- 인덱스는 쓰기가 완료될 때마다 업데이트된다.
accounts 업데이트는 copy-on-write 방식으로 랜덤 SSD에 추가되므로, 솔라나는 동시 트랜잭션을 위한 많은 SSD 사이 쓰기에서 순차성 및 수평적 확장의 이점을 얻는다. 읽기는 여전히 랜덤 접근이지만 주어진 fork 상태 업데이트가 여러 SSD에 분산되어 있기 때문에 읽기도 수평적으로 확장된다.
❓ Copy-On-Write(COW)이란
리소스가 복제되었지만 수정되지 않은 경우에, 새 리소스를 만들 필요 없이 복사본과 원본이 리소스를 공유하고, 복사본이 수정되었을 때만 새 리소스를 만드는 관리 기법을 말한다.
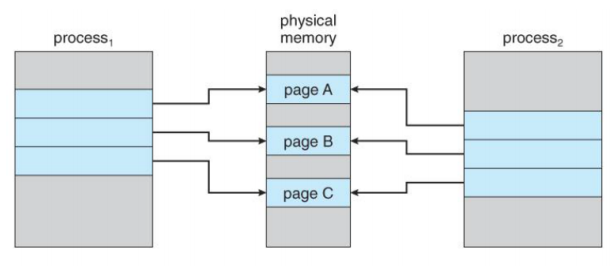
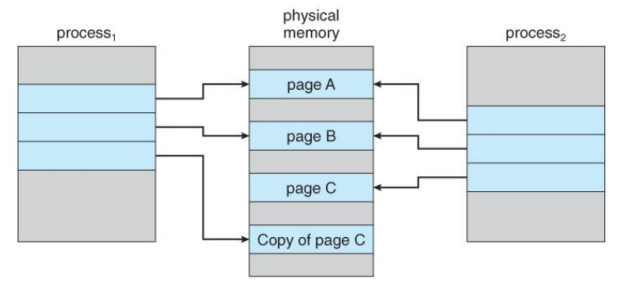
OS에서 COW는 fork()와 관련이 깊다. fork()를 수행하면 자식 프로세스가 부모 프로세스의 복사본이 된다. 이 때 동일한 리소스를 실제로 복제한다면 overhead가 발생하게 되므로 비효율적이다. 따라서 COW를 이용해 자식 프로세스가 부모 프로세스와 같은 페이지를 공유하게 한다. 만약 자식 프로세스에 수정이 일어난다면 그 때 Copy를 실행한다.
이렇게 내용이 바뀌지 않을 때는 같은 페이지를 공유하고, 내용이 변경될 때 새로운 페이지를 할당해서 복사하여 복사에 드는 비용을 감소시키는 기법이 COW이다.
Cloudbreak는 일종의 가비지 콜렉터 기능도 수행한다. fork가 롤백을 넘어서 최종적으로 완료되고, account가 업데이트되면 오래되고 유효하지 않은 account가 수집되고 메모리가 양도된다.
이 아키텍처에는 적어도 하나 이상의 큰 이점이 있다. 주어진 fork에 대한 상태 업데이트의 머클 루트를 계산하는 것을 SSD에서 수평으로 확장되어있는 순차적 읽기로 수행할 수 있다는 것이다. 이 접근 방식의 단점은 데이터에 대한 일반성이 손실된다는 것이다. 이것은 사용자 정의 레이아웃이 있는 사용자 정의 데이터 구조이므로 데이터 쿼리 및 조작에 범용 DB 추상화를 사용할 수 없다. 그래서 우리는 맨 밑바닥부터 모든 것을 구축해야 했으나, 다행히 지금은 모두 완성되었다.
Cloudbreak 벤치마킹

account DB가 RAM에 있는 동안, 사용 가능한 코어 수에 따라 확장하면서 RAM 접근 시간과 일치하는 처리량을 확인할 수 있다. 천만 개의 accounts일 때 DB는 더 이상 RAM에 맞지 않다. 그러나 단일 SSD에서 초당 읽기 또는 쓰기 성능은 여전히 1m에 가까운 것을 확인할 수 있다.